
こんにちは。EAGLYS MIリサーチャー&エンジニアの温です。
2025年1月、IBMが材料開発用のオープンソースAIモデル「FM4M(Foundation Model for Materials)」をリリースしました。 「半導体プロセス、クリーン・エネルギー、消費者向けパッケージングなどの分野における、サステナブルな新しい材料の発見を加速すること」を目的とするAIモデルです。
FM4Mは「材料をどう見るか」という視点を自由に選べる、モジュール型のAIモデルです。 一つの視点だけでなく、複数の視点から分子や材料を深く理解することができます。例えば分子構造の文字列表現(SMILES)や、点と線のグラフ、原子の3D構造、さらにはグリッド状に表示された電子密度分布など、さまざまな情報を統合して扱えるのが特徴です。
研究の現場では「この構造ってどんな性質がありそう?」と、日々考えることが多くあります。FM4Mのようなモデルがあれば、そういった問いにすぐ応えてくれる時代が来るかもしれません。複雑な材料特性の予測が、今よりもっと身近になる日もそう遠くないのはでないでしょうか?
そんなFM4Mについて、日本語の情報がプレスリリース以外ほとんど見当たらなかったので、今回は日本語でFM4Mを紹介していきます。
アーキテクチャ / ユニモーダルとマルチモーダル
FM4Mの使い方は2通りあります。

- ・ユニモーダル(UM)モデル
SMILESデータをオートエンコーダを介して潜在変数を生成。そして生成された潜在変数を用いて、Downstream task(下流タスク)のフェーズで化合物の物性の予測、収率の予測、望ましい物性の分子を生成するなどのタスクを行うことができます。 - ・マルチモーダル(MM)モデル
SMILES以外に、グラフ、未実装のテキストとスペクトルなどのデータを、それぞれ個別のユニモーダルモデルから潜在変数を生成。そして同じく生成された潜在変数を用いて、下流タスクのフェーズで予測などを行えます。
どちらのパターンでも、前段の青色のブロックは、潜在変数を生成するモデルの部分になります。そして生成された潜在変数を用いて、その後の下流タスクに予測AIモデルを構築。物性予測や、理想の分子を生成するといったことに活用可能です。
5つのユニモーダルモデル
1. SMI-TED(SMILES-based Transformer Encoder-Decoder)
PubChemから抽出された約9,100万件のSMILESデータ(約40億トークン)で事前学習されたオートエンコーダモデルです。量子特性予測などの複雑なタスクに対応しています。

引用元:https://huggingface.co/collections/ibm/materials-673465deacbdf38d9c0c6303
2. SELFIES-TED(SELFIES-based Transformer Encoder-Decoder)
SELFIES表記を用いたBARTベースのオートエンコーダモデルで、約10億件の分子データで事前学習されています。分子の表現学習と新規分子の生成が可能です。
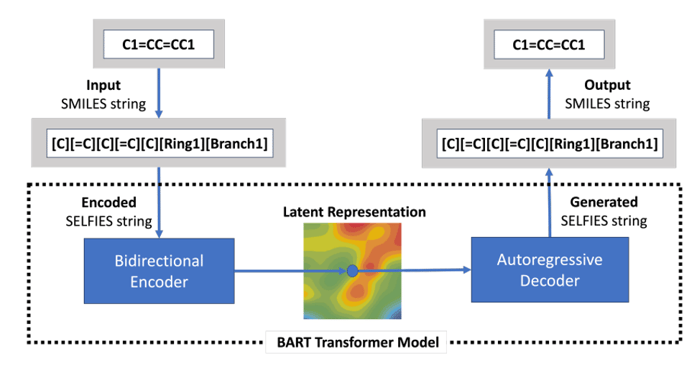
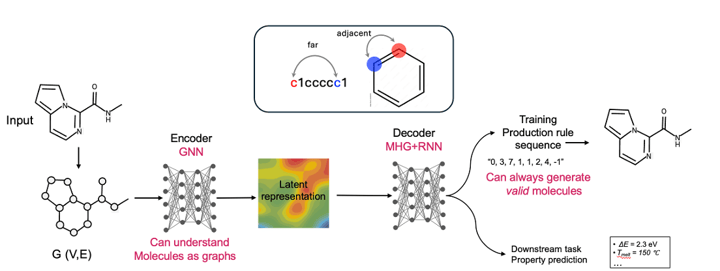
3. MHG-GED(Molecular Hypergraph Grammar with Graph-based Encoder Decoder)
グラフニューラルネットワーク(GNN)をベースとしたエンコーダと、分子ハイパーグラフ文法(MHG)に基づくデコーダを組み合わせたオートエンコーダモデルです。分子グラフデータに対して高い予測性能を持ち、常に構造的に有効な分子を生成することが保証されています。
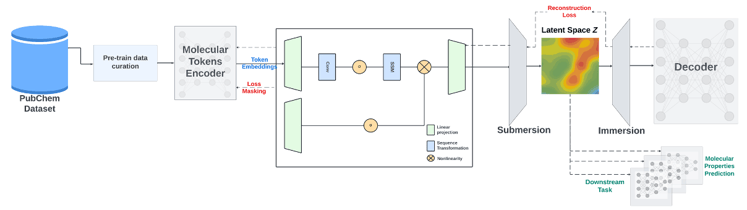
4. SMI-SSED(SMILES-based State-Space Encoder-Decoder)
Mambaアーキテクチャを採用したオートエンコーダモデルで、SMILESデータを用いて事前学習されています。効率的で高速な推論が可能です。
5. POS-EGNN(Position-aware Equivariant Graph Neural Network)
3D原子座標を入力として扱える等変性グラフニューラルネットワーク(Equivariant GNN)。空間構造に基づく精密な物性予測が可能で、構造依存性の高いタスクに有効です。
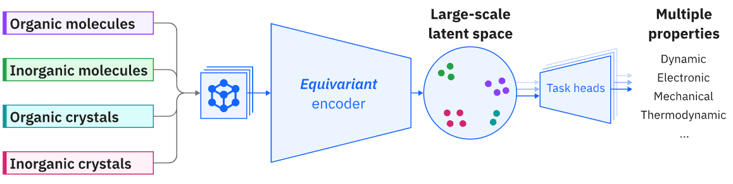
引用元:https://huggingface.co/ibm-research/materials.pos-egnn
マルチモーダルモデル
FM4Mでは、SMILESやSELFIESといった文字列表現だけでなく、分子グラフや3D構造といった異なる表現形式(モダリティ)を活用できます。MMモデルは、これら複数のモダリティから得られる情報を統合し、より正確かつロバストな予測を実現するための仕組みです。具体的には、各モダリティごとにUMモデルで生成された潜在変数を統合し、以下のような利点が得られます。
- ・複数視点の統合により物性予測精度の向上
・モダリティ間での情報補完(欠損耐性)
・予測だけでなく、生成や構造最適化など応用の幅の拡張
特に、材料開発では測定データが一部欠損していたり、複数の表現が混在することが多いため、MM設計は現実的な課題解決にも直結します。

各モデルの利用方法
各モデルはGithubから単独、もしくはPython環境から簡単に操作するためのFM4M Kitというラッパーで利用できます。
| 項目 | 単独利用 | FM4M Kit ラッパー利用 |
|---|---|---|
| SMI-TED | ○ | ○ |
| SELFIES-TED | ○ | ○ |
| MHG-GNN | ○ | ○ |
| SMI-SSED | ○ | × |
| POS-EGNN | ○ | ○ |
| Multi-modal model | × | ○ |
| Downstream Task 予測 | ○ (sklearnのライブラリーを使用) | ○ |
| Downstream Task 最適化 | × | × |
Web UIも提供
IBMは、Hugging Face Spaces上でFM4M Kitを用いたWeb UIを提供しています。このインターフェースにより、直感的な操作が可能。デモ画面を見る限り、結構グラフィカルで見やすそうです。データの選択、モデルの構築、下流タスクのトレーニング、基本的な結果の視覚化まで一連の操作ができます。

考えられる応用方法
新規材料候補のスクリーニング
数百万件の分子から、目標物性に近いものを高速に選別可能。
リード化合物の構造最適化
既知化合物に類似した候補を生成し、性能改善やコスト削減を支援。
合成ルートの優先順位づけ(将来的応用)
合成収率や反応性の予測により、実験前のプロトコル設計が効率化。
バッテリー材料や触媒の構造探索
構造-性能相関を学習し、高性能化に向けた分子設計の加速に貢献。
逆設計:所望の物性から分子を生成
ターゲット物性に合致する分子構造を提案する、いわゆる“AI材料発見”が可能。
FM4Mの強みは、多様な種類のデータを活用するマルチモーダルモデルの構築にあると考えています。化学の分野では、実験データがスパース(まばら)であることがよくあり、これは化学データベースを構築する際に大きな課題となります。 これまでにも、スパースなデータを補完するための欠損値処理の手法が複数提案されてきましたが、手法ごとにバイアスが生じたり、特定のデータの前提に依存したりする問題がありました。
その点、FM4Mのように異なる種類のデータ(マルチモーダル)を組み合わせたモデルであれば、それぞれのデータが補完し合うことで、より信頼性の高い欠損データの再現が可能になると期待しています。
参考文献
IBM「IBM、材料発見のためのオープンなAIモデルを発表」
https://jp.newsroom.ibm.com/2025-01-16-blog-foundation-models-for-materials
IBM「materials」github
https://github.com/IBM/materials
IBM「Materials - ibm Collection」Hugging Face
https://huggingface.co/collections/ibm/materials-673465deacbdf38d9c0c6303
IBM「Position-based Equivariant Graph Neural Network」Hugging Face
https://huggingface.co/ibm-research/materials.pos-egnn
「Foundation Model for Material Science」
https://ojs.aaai.org/index.php/AAAI/article/view/26793
Profile
EAGLYS
MIリサーチャー&エンジニア
温庭立/Uen Tinnlea
東京大学 バイオエンジニアリング専攻 博士課程修了。データサイエンティストとしての経歴を経て、EAGLYSでMI分野の研究・開発に従事する。2024年には早稲田大学 創造理工学部講義 マテリアルズインフォマティクスα 講師も。日本語能力検定 N1
